

Recently I had a severe problem with SQL endpoints and I was required to build a quick workaround for this.
The problem brought to light details we don’t know about SQL Endpoints and the care we need to have.
SQL Endpoint has a Cache
The SQL Endpoint needs to retrieve data from the storage, but it keeps its own cache. The SQL Endpoint cache is refreshed every 15 seconds.

This means that between a notebook write data in a lakehouse and the SQL Endpoint make this data available, there may be a 15 second delay.
SQL Endpoint is a serverless object
This means that after a not specified timeout without receiving any access, the SQL Endpoint goes down.
Once the SQL Endpoint goes down, the 15 seconds refresh stop.
What does this mean?
This means that if our notebook pipelines are ingesting lots of data during the night and the SQL Endpoint is going down, the first users to query the SQL Endpoint in the morning will get outdated data.
Once the refresh happens, the data will be updated again.
Are we talking about 15 seconds?
This is information not documented. There are conflicting details which is not easy to figure out.
Frequency of the Refresh: Every 15 seconds
Manual triggering: Yes, we can manually trigger the refresh. It’s made available in the UI and through an undocumented API.
How long the refresh takes: When triggering manually, the refresh is asynchronous, but I can notice it lasting around 8 minutes.
How can an endpoint refresh triggered every 15 seconds take 8 minutes? This is conflicting information.
Very Specific Case – or not?
It’s easy to believe this is a very specific case which will eventually affect some users in the early morning and quickly be fixed, like an intermittent problem.
However, I was the one with no luck: In my project, the SQL Endpoints failed for a while and just stopped refreshing. No clear error message, no warning, nothing, they just stop refreshing and I was the selected to quickly build a manual refresh solution.
Manual SQL Endpoint Refresh – The Basics
There is a Fabric API to trigger the refresh. The semantic Kernel in Fabric helps us to to call Fabric API’s, by helping us build the address to be called and controlling the authentication.
An example of using the semantic kernel to call the refresh API is like this code below:
import sempy.fabric as fabric client = fabric.FabricRestClient() # URI for the call uri = f"/v1.0/myorg/lhdatamarts/{SQLendpoint_ID}" # This is the action, we want to take payload = {"commands":[{"$type":"MetadataRefreshCommand"}]} # Call the REST API response = client.post(uri,json= payload)
Observe the following key points about this code:
- The address of the API is relative. The semantic kernel take care of the actual address
- The semantic kernel take care of the authentication.
- The SQL Endpoint Id is part of the API address. Keep in mind the lakehouse id and SQL Endpoint Id are different.
- This specific API requires a payload with the specific command we want to request.
Refresh Execution Id
Each execution results in a BatchId identifying the execution. The execution is asynchronous. If we would like to retrieve the status of the execution, we will need this batch id.
The code below shows an example about how to retrieve the batch id from the response after triggering a refresh:
# return the response from json into an object we can get values from data = json.loads(response.text) # We just need this, we pass this to call to check the status batchId = data["batchId"]
The execution can take up to 8 minutes. You can’t trigger a refresh when there is one already executing, you need to check the status of the existing refresh to decide if you can trigger a new one or not.
Refresh Status and why to check it
The first thing we can imagine is that you can just make a refresh call at the end of the data ingestions and it will work.
However, if your data ingestions are happening in high frequency and you have many of them, probably you will end up trying to trigger the same refresh multiple times and receiving errors.
You need to store the information about the last refreshes triggered. At the end of every ingestion, you check the refresh status. If it is finished, you trigger it again.
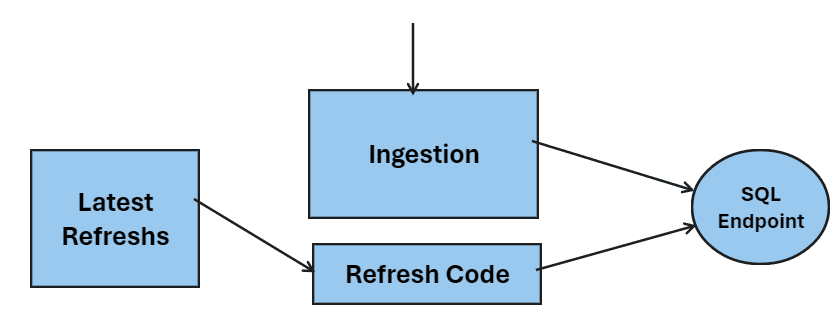
How to check the SQL Endpoint Refresh Status
The draft code below shows an example about how to check the status of a refresh:
# URL so we can get the status of the sync statusuri = f"/v1.0/myorg/lhdatamarts/{SQLendpoint_ID}/batches/{batch_id_value}" # turn response into object statusresponsedata = client.get(statusuri).json() # get the status of the check progressState = statusresponsedata["progressState"] if (progressState=="inProgress"): mssparkutils.notebook.exit(0) else: print(progressState)
Let’s highlight some important details in the code
- The URL uses SQL Endpoint Id and the batch id. You need to have the batch id of the last refresh request stored somewhere, so you will be able to check it.
- The semantic kernel completes the URL and makes the authentication, we only need the client object
- We extract progressState from the resulting JSON
Summary
SQL Endpoint has secrets capable of causing problems. Either in regular scenarios (no usage, serverless starting) or in exception scenarios (SQL Endpoint usual refresh failing).
This undocumented API can help us workaround the problems



Load comments